Trigonometry of Positional Embeddings
It is well known fact that Transformer models uses positional embeddings to encode positional information during the attention calculation for each pair of token embeddings. Prior to Transformers, we had RNN and LSTM which intrinsically handled the sequence information. But with Transformers and attention mechanism, standard dot product between pairs of token embeddings do not maintain the position information.
For e.g. given a sentence such as “The apple fell from the tree on my apple macbook”. The token embedding for “apple” at position 2 is the same as the token embedding at position 9 but they imply different objects given the sequence of words. Without positional encodings, attention mechanism will give the same dot product (query and key) for position 2 and 9 when we compute Q.K^T.
But how does one design “good” positional embeddings that meets the following conditions:
- Should be able to handle arbitrary sequence lengths. Not just the maximum sequence length encoutered during training.
- Same token at different positions should have different positional embeddings.
- For any two positions
pandqin the sequence, iffis the function for computing the positional embedding andkis some distance, then|f(p+k)-f(q+k)|=|f(p)-f(q)|or|f(p+k)-f(p)| = |f(q+k)-f(q)|
The last condition implies that the absolute difference of the positional embeddings between 2 positions is only dependent on the distance between the positions in the sequence. This is important because it implies that words or tokens are only affected by its neighboring words.
The last condition implies that the function f should be some form of rotation or linear transformation. For e.g. given the linear transformation f(x) = ax + b, we see that it satisfies the last condition where a and b can be learnable parameters. For Transformer use case, x must be a tensor of shape (batch, seq_len, emb_dim). Thus the learnable parameter a must be a weight matrix of shape (seq_len, seq_len).
But note that this formulation violates condition 1 above because if a is of shape (100, 100) for a sequence length of 100 encoutered during training then we cannot use this to compute f(x) when x is of shape (200, 16) encountered during inference because the last dimension of a must match with the 1st dimension of x for dot product calculations.
The other possibility is rotation i.e. f(x)=e^(iwx) where i is the imaginary square root of unity i*i=-1 and w is the frequency of rotation. Expanding using Euler’s formula, we can also write it as e^(iwx) = cos(wx) + i*sin(wx). Note that none of the parameters in the equation of rotation depends on the sequence length.
Let’s prove the equation |f(p+k)-f(q+k)|=|f(p)-f(q)|.
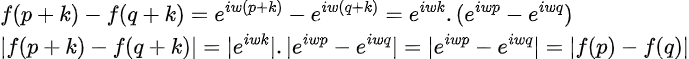
We can also show that the rearranged quantity |f(p+k)-f(p)| is independent of the position p as follows:

Now, let us represent the positional embedding vector of dimension d for position p as follows:
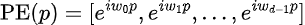
where w_j is the frequency of rotation and j is the index within the d-dimensional embedding i.e. each dimension of the positional embedding represents a rotation with a different frequency.
But now we have another problem, the positional embeddings are all a bunch of complex numbers. If we take only the real part out of each rotation as follows i.e.
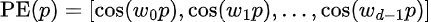
and we compute the absolute distance between embeddings distance k apart as follows:
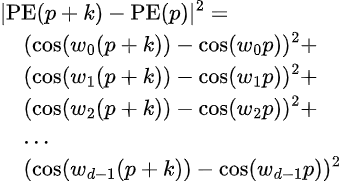
We cannot reduce the above into an expression that is independent of p as we saw above when we used the full complex representation instead of just the real part. One way to resolve this is to group the embedding values in groups of 2 i.e. assuming that the embedding dimension is divisible 2, then for each group of 2, we alternate between the cosine or the real part and the sine part or the imaginary part, and the embedding vector looks as follows:
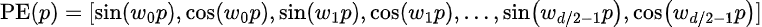
Then we compute the absolute distance between embeddings distance k apart as follows:
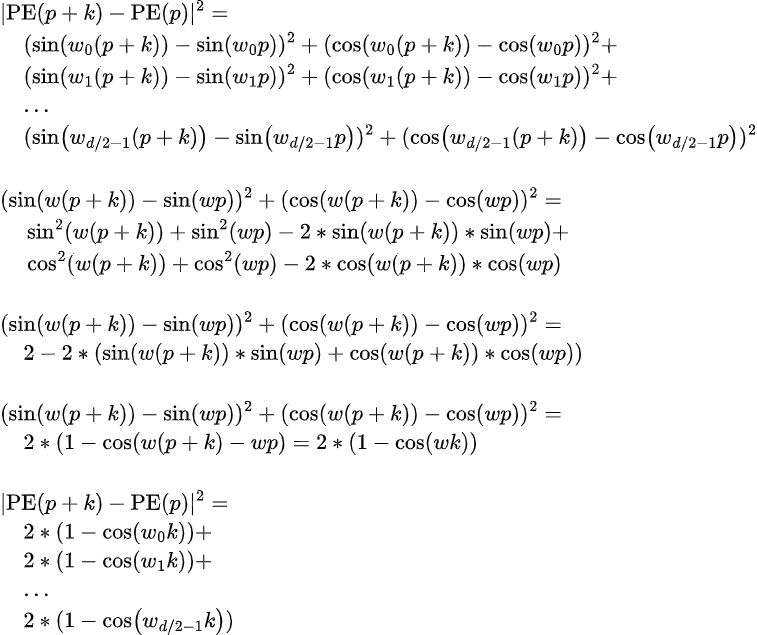
Thus, we can see that the absolute difference is independent of the position p within the sequence when we use both sine and cosine alternately. In the original Transformer paper, the values of the frequency are as follows:
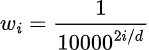
One can also write the Euler’s formula in terms of matrix notation as follows:
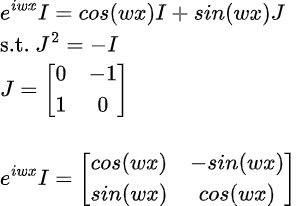
If you observe, in the matrix notation, there are no imaginary terms in the rotation matrix. The matrix notation comes handy for computing the positional embedding vector for different positions in the sequence. If you observe, then we see that one can obtain PE(p+k) from PE(p) above by multipying a block diagonal rotation matrix with PE(p) as follows:

One more issue that arises in the attention mechanism is that the positional embeddings are added to the input tensor and then the query and key tensors are computed by multiplying with the corresponding weight matrices and finally their dot product Q.K^T. In all of these processes, the final dot product Q.K^T do not preserve the condition 3 describe earlier.
In the context of the dot product let <qu, kv> denote the dot product between the query vector for the u-th token in the sequence and the key vector for the v-th token in the sequence, then let f(q,u) denote the query vector including positional encoding and g(k,v) denote the key vector including positional encoding then a modified version of condition 3 for dot product would be:
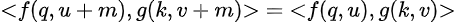
i.e. the dot product of the query vector and key vector with positional encoding included should only depend on the relative distance between the query and key token within the sequence. We can check that addition of positional embeddings to input doesn’t satisfy the above condition. The above condition is satisfied if we consider rotations of Q and K as follows:
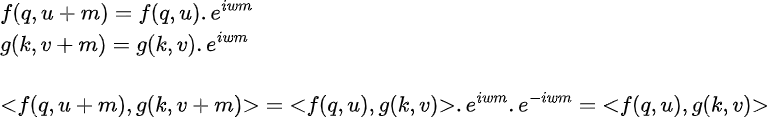
The 2nd term g(k, v+m) is transposed hence e^(-iwm). The terms f(q, u) and f(k, v) are called RoPE embeddings and they include both token as well positional information.