CUDA GEMMS
Matrix multiplication is the building block of Deep Neural Networks which in turn are the building blocks of all AI models and applications. In order to scale AI models to billions of parameters, one must thus scale matrix multiplication. Given matrices A and B of shapes MxK and KxM, the dot product C=A.B is of shape MxN. This is what probably 90% of neural networks do.
Time complexity of computing C=A.B is O(MxNxK) or if all dimensions are same then it is O(M^3). Algorithmically, one cannot improve the time complexity much although some algorithms exists such as Strassen's Algorithm which does matrix multiplication in O(M^2.8) operations. Even the advanced algorithms today cannot achieve better than O(M^2.371).
Strassen’s Algorithm for Matrix Multiplication
CopperSmith-Winnograd Matrix Multiplication
So algorithmically one cannot improve the run-time performance too much. The other strategy is to use massive parallelization.
On CPU, one can use multiple threads to calculate multiple output elements of C in parallel. For e.g. multithreading using openmp in C++ improves the run-time of multiplying 2 matrices of shapes 1024x1024 from 2688 ms to 555 ms using 8 threads i.e. an improvement of around 5x.
void gemm_cpu(
const float *a,
const float *b,
float *c,
const float alpha,
const float beta,
const unsigned int m,
const unsigned int n,
const unsigned int k
) {
omp_set_num_threads(8);
#pragma omp parallel for shared(a, b, c)
for(auto i = 0; i < m; i++) {
for (auto j = 0; j < n; j++) {
float r = 0.0f;
for (auto q = 0; q < k; q++) r += a[i*k+q]*b[q*n+j];
c[i*n+j] = alpha*r + beta*c[i*n+j];
}
}
}
The above function computes the GEMM (General Matrix Multiply) where D=alpha*A.B + beta*C. For standard matrix multiplication A.B we can consider alpha=1.0 and beta=0.0.
CPU is limited by the number of threads because CPUs are optimized for lowering the latency of a single process instead of solving problems in parallel. Most commercially available CPUs have at-most 64 cores. On the other hand modern GPUs have thousands of cores or threads to perform GEMM in parallel (SIMD or SIMT Single Instruction Multiple Data/Threads) and that would be the topic of this post. We will try to optimize GEMM on GPUs by leveraging different CUDA kernel optimization strategies.
Before we begin exploring kernels, one should keep in mind that not all GPU architectures are built same and the same kernel A that performs better than kernel B on a GPU arch X, may perform worse than kernel B on another GPU arch Y. Importantly you should write your kernels keeping in mind the GPU architecture of your compute nodes or pods.
Also for the same architecture, matrices of different dimensions shows different relative performance for different kernels. For e.g. say on L4 GPU, if kernel 1 performs better than kernel 2 on 1024x1024 matrices it does not imply that kernel 1 will still perform better than kernel 2 on 4096x4096 matrices due to various factors such as availability of resources.
All of the kernels I am going to show here are written on L4 GPUs and so the performance numbers are w.r.t. the L4 GPUs only. The numbers might change drastically if you run the same kernel on say H100 or A100 or RTX. Also the kernels are written very specific towards particuar shapes for e.g. matrix dimensions with powers of 2. The kernels do not handle edge cases for incomplete blocks.
All the codes are available at my github repository.
Kernel 1 - Standard CUDA
__global__
void gemm_fp32_cuda(
const float *a_fp32,
const float *b_fp32,
float *c_fp32,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
int row = blockIdx.y*blockDim.y + threadIdx.y;
int col = blockIdx.x*blockDim.x + threadIdx.x;
if (row < m && col < n) {
float res = 0.0f;
for (int i = 0; i < k; i++) res += a_fp32[row*k+i]*b_fp32[i*n+col];
c_fp32[row*n+col] = alpha*res + beta*c_fp32[row*n+col];
}
}
float *c_gpu_fp32_ccores;
cudaErrCheck(cudaMallocManaged(&c_gpu_fp32_ccores, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_fp32_ccores[i] = 0.0f;
dim3 bd(32, 32, 1);
dim3 gd((n+31)/32, (m+31)/32, 1);
gemm_fp32_cuda<<<gd, bd>>>(a_fp32, b_fp32, c_gpu_fp32_ccores, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_fp32_ccores));
In CUDA, each block of threads can have at-most 1024 threads. It is upto you how you want to distribute the threads across multiple dimensions. For e.g. in the above kernel each block is 2D and thus each dimension has 32 threads totalling 32*32=1024 threads. Note that in the dimensions defined above, the 1st dimension (x) corresponds to number of columns and 2nd dimension (y) corresponds to number of rows.
Total number of blocks required to populate the entire output matrix along the column dimension is ceil(n/32) or (n+31)/32 where n is the number of columns in output matrix and along the row dimension is (m+31)/32. In the above kernel, each thread is responsible for computing one element of the output matrix.
Time taken to multiply two 4096x4096 matrices is around 40.4367 ms.
To compile all the CUDA kernels on L4 GPU, I use the following command from the terminal. Make sure you have the necessary libraries such as TBB or OpenMP installed.
nvcc \
-rdc=true *.cu \
-Xcompiler -fopenmp \
-o my_gemm \
-O3 \
-Xcompiler -O3 \
--gpu-code=sm_89 \
-arch=compute_89 \
-lcublas \
-lcurand \
-ltbb
Kernel 2 - 1D Tiling + Thread Coarsening
#define COARSE_FACTOR 4
#define TILE_WIDTH 32
__global__
void gemm_fp32_cuda_tiled(
const float *a_fp32,
const float *b_fp32,
float *c_fp32,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
__shared__ float Mds[TILE_WIDTH*TILE_WIDTH];
__shared__ float Nds[TILE_WIDTH*TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row = by*TILE_WIDTH + ty;
int col_start = bx*TILE_WIDTH*COARSE_FACTOR + tx;
float Pval[COARSE_FACTOR];
for (int r = 0; r < COARSE_FACTOR; r++) Pval[r] = 0.0f;
for (int ph = 0; ph < k; ph += TILE_WIDTH) {
if (row < m && (ph + tx) < k) Mds[ty*TILE_WIDTH+tx] = a_fp32[row*k + ph + tx];
else Mds[ty*TILE_WIDTH+tx] = 0.0f;
for (int r = 0; r < COARSE_FACTOR; r++) {
int col = col_start + r*TILE_WIDTH;
if ((ph + ty) < k && col < n) Nds[ty*TILE_WIDTH+tx] = b_fp32[(ph + ty)*n + col];
else Nds[ty*TILE_WIDTH+tx] = 0.0f;
__syncthreads();
for (int i = 0; i < TILE_WIDTH; i++) Pval[r] += Mds[ty*TILE_WIDTH+i]*Nds[i*TILE_WIDTH+tx];
__syncthreads();
}
}
for (int r = 0; r < COARSE_FACTOR; r++) {
int col = col_start + r*TILE_WIDTH;
if (row < m && col < n) c_fp32[row*n+col] = alpha*Pval[r] + beta*c_fp32[row*n+col];
}
}
float *c_gpu_fp32_tiled;
cudaErrCheck(cudaMallocManaged(&c_gpu_fp32_tiled, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_fp32_tiled[i] = 0.0f;
dim3 bd1(32, 32, 1);
dim3 gd1((n+32*COARSE_FACTOR-1)/(32*COARSE_FACTOR), (m+31)/32, 1);
gemm_fp32_cuda_tiled<<<gd1, bd1>>>(a_fp32, b_fp32, c_gpu_fp32_tiled, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_fp32_tiled));
As before, we have a blocks of threads where each block has 32 threads per row and there are 32 such rows totalling 1024 threads per block. But now each thread is responsible for computing 4 elements (COARSE_FACTOR=4). Thus each block now computes the output elements equivalent to 4 blocks as in the previous kernel. Thus number of blocks required will reduce along the column (x) dimension to (n+127)/128.
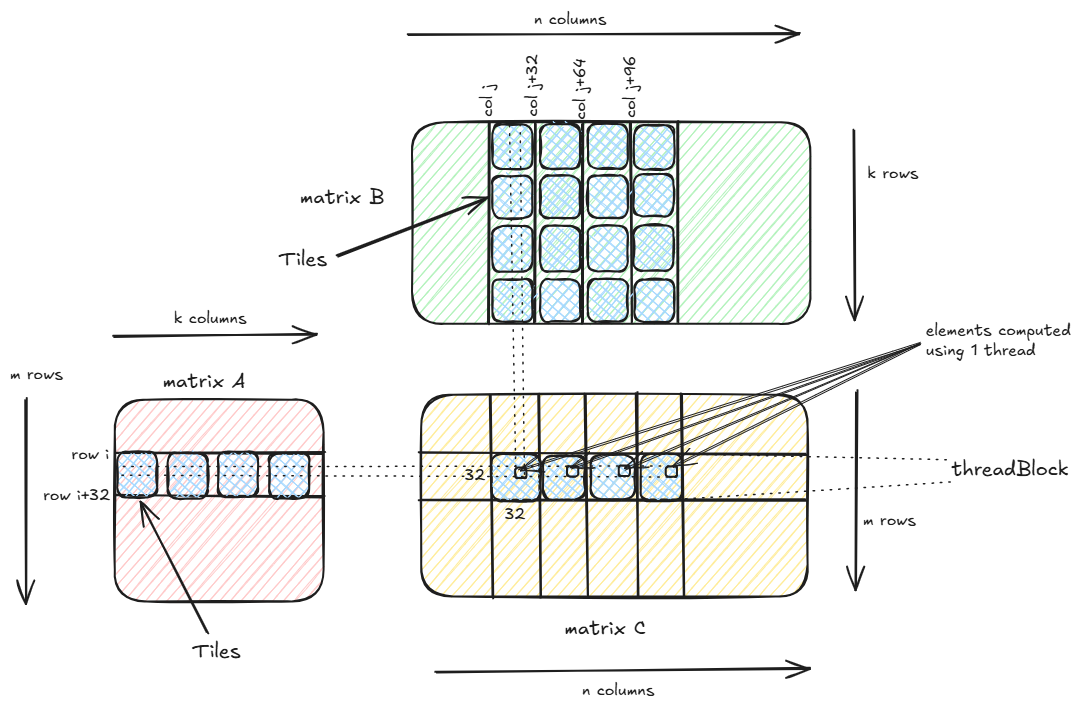
Also, another important technique used to optimize the kernel is Tiling. In Tiling, instead of each thread reading a full row i of matrix A and a full column j of matrix B from the global memory to compute C[i,j], each thread now reads TILE_WIDTH=32 elements from row i in A and TILE_WIDTH=32 elements from column j in B at a time, loads them from global memory to shared memory and computes the partial sum for C[i,j]. Once a tile from A and B has been read and partial sum is computed, the next tile from A and B is read by the thread to get the next 32 elements of row i in A and next 32 elements of column j in B and the process is repeated. To understand why this works:
C[i,j] = A[i,0]*B[0,j] + A[i,1]*B[1,j] + ... + A[i,k]*B[k,j]
Assuming each tile is of size 32 and k=4096, then there would be 128 tiles.
C_tile_0[i,j] = A[i,0]*B[0,j] + A[i,1]*B[1,j] + ... + A[i,31]*B[31,j]
C_tile_1[i,j] = A[i,32]*B[32,j] + A[i,33]*B[33,j] + ... + A[i,63]*B[63,j]
C_tile_2[i,j] = A[i,64]*B[64,j] + A[i,65]*B[65,j] + ... + A[i,95]*B[95,j]
....
C_tile_127[i,j] = A[i,4064]*B[4064,j] + A[i,4065]*B[4065,j] + ... + A[i,4095]*B[4095,j]
Then we have,
C[i,j] = C_tile_0[i,j] + C_tile_1[i,j] + ... + C_tile_127[i,j]
The reason for Tiling is to reduce the latency in fetching data from the global memory of the GPU. The process of Tiling is similar to caching where we pull the frequenctly accessed elements from RAM to L1/L2/L3 Cache.
Similar to memory hierarchy in CPU : Register > L1 > L2 > L3 > RAM, GPU has its own memory hierarchy which looks something like Register > Shared Memory > Global Memory. Similar to CPU, the higher performance memory are limited in size as compared to the lower performance memory i.e. shared memory is much smaller (48KB per block and 163KB per SM) as compared to global memory (around 24GB).
Shared memory is accessible by all threads in the block. Thus if thread T1 computes the element C[i,j] and thread T2 computed C[i,j+1], then note that we only need to read the row i from global memory to shared memory once for all columns corresponding to row i in the output matrix C. But since shared memory size is limited we resort to use tiling i.e. read 32 elements from row i at a time.
In the above kernel, each thread computes 4 elements C[i,j], C[i,j+32], C[i,j+64] and C[i,j+96]. This is because consecutive threads compute consecutive elements. Threads T0 to T31 computes C[i,j] to C[i,j+31]. Then the same threads computes C[i,j+32] to C[i,j+63] and so on. A group of 32 consecutive threads is called a Warp and a Warp is scheduled to run simultaneously, thus threads T0 to T31 is accessing consecutive memory locations and thus require a single GPU cycle to read all 32 consecutive elements.
In matrix multiplication, multiplying two k length vectors requires 2*k operations (k multiplications + k additions). Multiplying two matrices of size TILE_WIDTH*TILE_WIDTH requires 2*TILE_WIDTH^3 operations. The number of bytes transferred in the above kernel from global memory per ph is 8*TILE_WIDTH^2 bytes for Mds and 8*COARSE_FACTOR*TILE_WIDTH^2 bytes for Nds. Thus the ratio of operations per byte transferred is (2*COARSE_FACTOR*TILE_WIDTH^3)/(8*TILE_WIDTH^2 + 8*COARSE_FACTOR*TILE_WIDTH^2) which is 6.4 i.e. for every byte transferred from global memory, we are doing 6.4 operations.
Without tiling, to compute each element of output matrix C, we required 2*k operations (k columns) and transferred 16*k bytes from global memory in total. Thus the number of operations per byte transferred was 0.25. Thus with tiling we have improved the ratio by constant*TILE_WIDTH times. Note that the amount of shared memory usage per block is currently 16*TILE_WIDTH^2 bytes or 16KB. If we double the TILE_WIDTH, the shared memory usage will become 4 times i.e. 64KB which exceeds 48KB available per block. Thus, we cannot increase shared memory arrays arbitrarily to improve the ratio of number of operations per byte transferred from global memory.
Another important metric to look out for is that for a thread to compute a submatrix of size 1x4 for the output matrix C, it needs to load a sub-matrix of shape 1xk from A and a sub-matrix of shape kx4 from B. Thus in order to compute 4 output elements, the kernel needs to load k + 4k = 5k elements in total from global memory. The number of outputs per element loaded from global memory is 4/5k. This number will be useful when we look at the next kernel.
Time taken to multiply two 4096x4096 matrices is around 27.349 ms.
Kernel 3 - 2D Tiling + Thread Coarsening
#define COARSE_FACTOR_2D 4
#define TILE_WIDTH 32
__global__
void gemm_fp32_cuda_tiled_2D(
const float *a_fp32,
const float *b_fp32,
float *c_fp32,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
__shared__ float Mds[TILE_WIDTH*TILE_WIDTH];
__shared__ float Nds[TILE_WIDTH*TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row_start = by*TILE_WIDTH*COARSE_FACTOR_2D + ty;
int col_start = bx*TILE_WIDTH*COARSE_FACTOR_2D + tx;
float Pval[COARSE_FACTOR_2D*COARSE_FACTOR_2D];
for (int r = 0; r < COARSE_FACTOR_2D*COARSE_FACTOR_2D; r++) Pval[r] = 0.0f;
for (int ph = 0; ph < k; ph += TILE_WIDTH) {
for (int r = 0; r < COARSE_FACTOR_2D; r++) {
int row = row_start + r*TILE_WIDTH;
if (row < m && ph + tx < k) Mds[ty*TILE_WIDTH+tx] = a_fp32[row*k + ph + tx];
else Mds[ty*TILE_WIDTH+tx] = 0.0f;
for (int c = 0; c < COARSE_FACTOR_2D; c++) {
int col = col_start + c*TILE_WIDTH;
if (ph + ty < k && col < n) Nds[ty*TILE_WIDTH+tx] = b_fp32[(ph + ty)*n + col];
else Nds[ty*TILE_WIDTH+tx] = 0.0f;
__syncthreads();
for (int i = 0; i < TILE_WIDTH; i++) Pval[r*COARSE_FACTOR_2D + c] += Mds[ty*TILE_WIDTH+i]*Nds[i*TILE_WIDTH+tx];
__syncthreads();
}
}
}
for (int r = 0; r < COARSE_FACTOR_2D; r++) {
int row = row_start + r*TILE_WIDTH;
for (int c = 0; c < COARSE_FACTOR_2D; c++) {
int col = col_start + c*TILE_WIDTH;
if (row < m && col < n) c_fp32[row*n+col] = alpha * Pval[r*COARSE_FACTOR_2D + c] + beta * c_fp32[row*n+col];
}
}
}
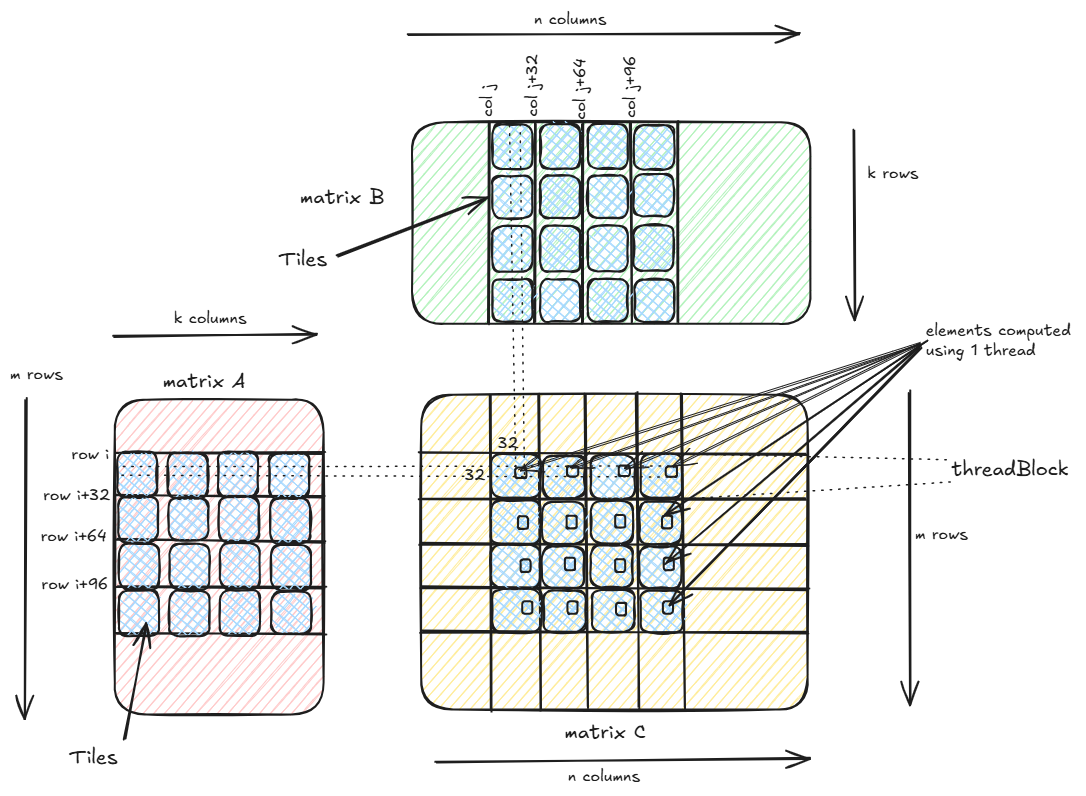
Instead of each thread computing 4 elements of the same row in the output matrix, in the above kernel each thread now computes 4x4 elements comprising of 4 rows and 4 columns of the output matrix. Apart from these most of the code is similar to the 1D Tiling kernel above. Let’s compute the number of operations per byte transferred with 2D tiling kernel.
Total number of operations in 4x4 blocks each with 32x32 elements = (2*COARSE_FACTOR_2D*COARSE_FACTOR_2D*TILE_WIDTH^3)
Total number of bytes transferred = (8*COARSE_FACTOR_2D*TILE_WIDTH^2 + 8*COARSE_FACTOR_2D*COARSE_FACTOR_2D*TILE_WIDTH^2) bytes.
Ratio of number of operations per byte transferred = (COARSE_FACTOR_2D*TILE_WIDTH)/(4*(1 + COARSE_FACTOR_2D)) = 6.4
Thus, the ratio of number of operations per byte transferred remains same as the previous kernel.
But note that in order to compute 4x4=16 elements of C, the kernel loads 4xk elements from A and kx4 elements from B, thus totalling 8k elements. The number of outputs per element loaded from global memory is 16/8k=2/k. Compare this to the previous kernel where number of outputs per element loaded from global memory was 0.8/k.
We can see that this kernel is more efficient because it computes more element for the same number of inputs loaded from global memory. This metric is useful because apart from shared memory, GPU also has L1/L2 cache similar to CPU and often elements fetched from global memory are cached for reuse.
Time taken to multiply two 4096x4096 matrices is around 23.7353 ms.
Kernel 4 - 2D Tiling + Vectorization
#define TILE_WIDTH 32
#define COARSE_FACTOR_2D 4
__global__
void gemm_fp32_cuda_tiled_2D_vectorize(
float *a_fp32,
float *b_fp32,
float *c_fp32,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
__shared__ alignas(16) float Mds[TILE_WIDTH*TILE_WIDTH];
__shared__ alignas(16) float Nds[TILE_WIDTH*TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row_start = by*TILE_WIDTH*COARSE_FACTOR_2D + ty;
int col_start = bx*TILE_WIDTH*COARSE_FACTOR_2D + tx*4;
float Pval[COARSE_FACTOR_2D*COARSE_FACTOR_2D*4];
for (int r = 0; r < COARSE_FACTOR_2D*COARSE_FACTOR_2D*4; r++) Pval[r] = 0.0f;
for (int ph = 0; ph < k; ph += TILE_WIDTH) {
for (int r = 0; r < COARSE_FACTOR_2D; r++) {
int row = row_start + r*TILE_WIDTH;
reinterpret_cast<float4 *>(&Mds[ty*TILE_WIDTH + tx*4])[0] = reinterpret_cast<float4 *>(&a_fp32[row*k + ph + tx*4])[0];
for (int c = 0; c < COARSE_FACTOR_2D; c++) {
int col = col_start + c*TILE_WIDTH;
reinterpret_cast<float4 *>(&Nds[ty*TILE_WIDTH + tx*4])[0] = reinterpret_cast<float4 *>(&b_fp32[(ph + ty)*n + col])[0];
__syncthreads();
for (int i = 0; i < TILE_WIDTH; i++) {
Pval[r*COARSE_FACTOR_2D*4 + 4*c + 0] += Mds[ty*TILE_WIDTH+i]*Nds[i*TILE_WIDTH+tx*4+0];
Pval[r*COARSE_FACTOR_2D*4 + 4*c + 1] += Mds[ty*TILE_WIDTH+i]*Nds[i*TILE_WIDTH+tx*4+1];
Pval[r*COARSE_FACTOR_2D*4 + 4*c + 2] += Mds[ty*TILE_WIDTH+i]*Nds[i*TILE_WIDTH+tx*4+2];
Pval[r*COARSE_FACTOR_2D*4 + 4*c + 3] += Mds[ty*TILE_WIDTH+i]*Nds[i*TILE_WIDTH+tx*4+3];
}
__syncthreads();
}
}
}
for (int r = 0; r < COARSE_FACTOR_2D; r++) {
int row = row_start + r*TILE_WIDTH;
for (int c = 0; c < COARSE_FACTOR_2D; c++) {
int col = col_start + c*TILE_WIDTH;
c_fp32[row*n + col + 0] = alpha*Pval[r*COARSE_FACTOR_2D*4 + 4*c + 0] + beta*c_fp32[row*n + col + 0];
c_fp32[row*n + col + 1] = alpha*Pval[r*COARSE_FACTOR_2D*4 + 4*c + 1] + beta*c_fp32[row*n + col + 1];
c_fp32[row*n + col + 2] = alpha*Pval[r*COARSE_FACTOR_2D*4 + 4*c + 2] + beta*c_fp32[row*n + col + 2];
c_fp32[row*n + col + 3] = alpha*Pval[r*COARSE_FACTOR_2D*4 + 4*c + 3] + beta*c_fp32[row*n + col + 3];
}
}
}
float *c_gpu_fp32_tiled_2d_vec;
cudaErrCheck(cudaMallocManaged(&c_gpu_fp32_tiled_2d_vec, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_fp32_tiled_2d_vec[i] = 0.0f;
dim3 bd3(8, 32, 1);
dim3 gd3((n+32*COARSE_FACTOR_2D-1)/(32*COARSE_FACTOR_2D), (m+32*COARSE_FACTOR_2D-1)/(32*COARSE_FACTOR_2D), 1);
gemm_fp32_cuda_tiled_2D_vectorize<<<gd3, bd3>>>(a_fp32, b_fp32, c_gpu_fp32_tiled_2d_vec, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_fp32_tiled_2d_vec));
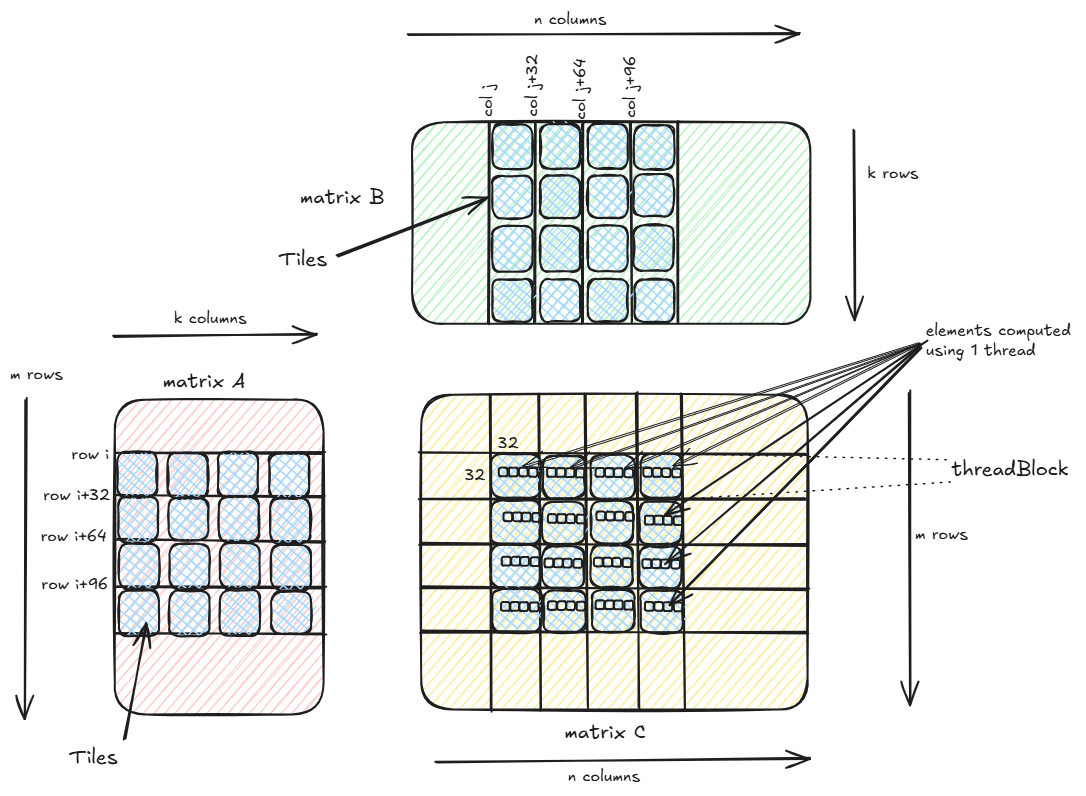
In the above kernel we are using vectorization with float4 data type i.e. instead of a thread loading a 32-bit float from global memory, a thread loads a 128-bit float4 or 4 consecutive 32-bit addresses. Instead of 4 instructions, now we have to issue only one instruction.
reinterpret_cast<float4 *>(&Mds[ty*TILE_WIDTH + tx*4])[0] = reinterpret_cast<float4 *>(&a_fp32[row*k + ph + tx*4])[0];
reinterpret_cast<float4 *>(&Nds[ty*TILE_WIDTH + tx*4])[0] = reinterpret_cast<float4 *>(&b_fp32[(ph + ty)*n + col])[0];
In order to work with float4 vectorization the x-dimension for each block of thread is reduced by a factor of 4 from the previous kernel i.e. instead of each thread computing 4x4=16 elements of the output matrix, now each each thread computes 4x4x4=64 elements.
Note that having many threads per block is not always good because GPU has what is known as the occupancy problem. Basically the resources such as number of registers, number of warps that can be simulataneously scheduled, maximum shared memory per block, maximum registers per thread are limited. When number of threads are higher, it can lead to smaller concurrency due to exceeding number of registers per thread or shared memory size etc. So often you would see that lesser number of threads perform better than more number of threads.
Note that the shared memory addresses needs to be 16 byte or 128-bit aligned using alignas(16).
Time taken to multiply two 4096x4096 matrices is around 15.1583 ms.
Kernel 5 - 2D Tiling + Asynchronous Pipelining N-Stage
#define TILE_WIDTH 32
#define COARSE_FACTOR_2D 4
#define NUM_STAGES_ASYNC_PIPELINE 4
__global__
void gemm_fp32_cuda_tiled_2D_async(
const float *a_fp32,
const float *b_fp32,
float *c_fp32,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
cuda::pipeline<cuda::thread_scope_thread> pipeline = cuda::make_pipeline();
__shared__ alignas(16) float Mds[NUM_STAGES_ASYNC_PIPELINE][TILE_WIDTH*TILE_WIDTH];
__shared__ alignas(16) float Nds[NUM_STAGES_ASYNC_PIPELINE][TILE_WIDTH*TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row_start = by*TILE_WIDTH*COARSE_FACTOR_2D + ty;
int col_start = bx*TILE_WIDTH*COARSE_FACTOR_2D + tx*4;
for (int r = 0; r < COARSE_FACTOR_2D; r++) {
int row = row_start + r*TILE_WIDTH;
for (int c = 0; c < COARSE_FACTOR_2D; c++) {
int col = col_start + c*TILE_WIDTH;
for (int s = 0; s < NUM_STAGES_ASYNC_PIPELINE; s++) {
pipeline.producer_acquire();
cuda::memcpy_async(Mds[s] + ty*TILE_WIDTH + tx*4, a_fp32 + row*k + s*TILE_WIDTH + tx*4, cuda::aligned_size_t<4>(sizeof(float)*4), pipeline);
cuda::memcpy_async(Nds[s] + ty*TILE_WIDTH + tx*4, b_fp32 + (s*TILE_WIDTH + ty)*n + col, cuda::aligned_size_t<4>(sizeof(float)*4), pipeline);
pipeline.producer_commit();
}
int s = NUM_STAGES_ASYNC_PIPELINE;
float res[4] = {0.0f};
for (int ph = 0; ph < k; ph += TILE_WIDTH) {
int stage = s % NUM_STAGES_ASYNC_PIPELINE;
constexpr size_t pending_batches = NUM_STAGES_ASYNC_PIPELINE - 1;
cuda::pipeline_consumer_wait_prior<pending_batches>(pipeline);
__syncthreads();
for (int i = 0; i < TILE_WIDTH; i++) {
res[0] += Mds[stage][ty*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+0];
res[1] += Mds[stage][ty*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+1];
res[2] += Mds[stage][ty*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+2];
res[3] += Mds[stage][ty*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+3];
}
pipeline.consumer_release();
__syncthreads();
pipeline.producer_acquire();
if (s*TILE_WIDTH < k) {
cuda::memcpy_async(Mds[stage] + ty*TILE_WIDTH + tx*4, a_fp32 + row*k + s*TILE_WIDTH + tx*4, cuda::aligned_size_t<4>(sizeof(float)*4), pipeline);
cuda::memcpy_async(Nds[stage] + ty*TILE_WIDTH + tx*4, b_fp32 + (s*TILE_WIDTH + ty)*n + col, cuda::aligned_size_t<4>(sizeof(float)*4), pipeline);
}
pipeline.producer_commit();
s += 1;
}
c_fp32[row*n+col+0] = alpha * res[0] + beta * c_fp32[row*n+col+0];
c_fp32[row*n+col+1] = alpha * res[1] + beta * c_fp32[row*n+col+1];
c_fp32[row*n+col+2] = alpha * res[2] + beta * c_fp32[row*n+col+2];
c_fp32[row*n+col+3] = alpha * res[3] + beta * c_fp32[row*n+col+3];
}
}
}
float *c_gpu_fp32_tiled_2d_async;
cudaErrCheck(cudaMallocManaged(&c_gpu_fp32_tiled_2d_async, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_fp32_tiled_2d_async[i] = 0.0f;
dim3 bd21(8, 32, 1);
dim3 gd21((n+32*COARSE_FACTOR_2D-1)/(32*COARSE_FACTOR_2D), (m+32*COARSE_FACTOR_2D-1)/(32*COARSE_FACTOR_2D), 1);
gemm_fp32_cuda_tiled_2D_async<<<gd21, bd21>>>(a_fp32, b_fp32, c_gpu_fp32_tiled_2d_async, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_fp32_tiled_2d_async));
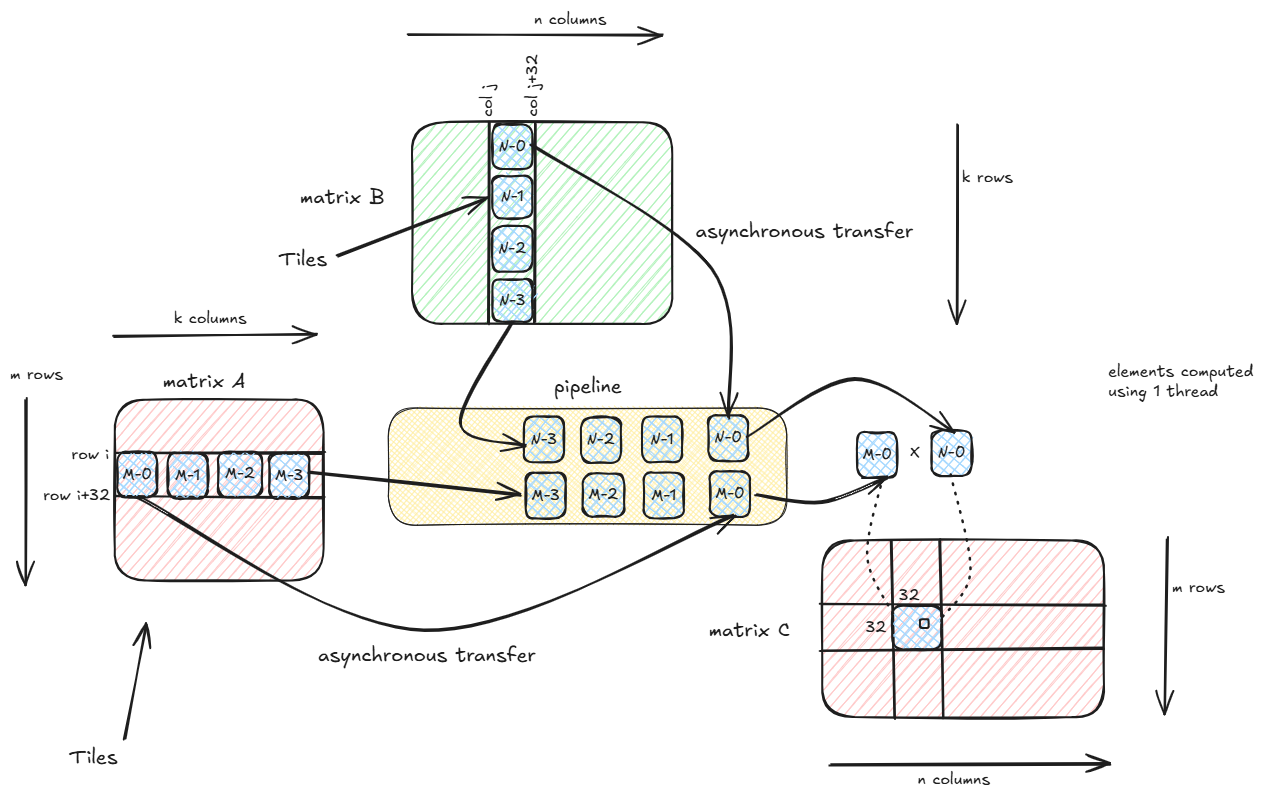
CUDA pipeline is something similar to a FIFO Queue. There is a producer pushing stages to the end of the queue while the consumer is reading the stages off the front of the queue.
Recall that in the 2D kernel, each thread computes 4x4x4=64 elements of the output matrix. To compute each output element, we use tiles that slide over the matrix A along the columns and over matrix B along rows. For k=4096 and tile dimension of 32x32, to compute each element one needs to slide over 128 tiles in both A (horizontally) and B (vertically). In the original 2D kernel, we slide over each tile one by one.
Instead what if in the meantime the threads that are multiplying the shared memory matrices Mds and Nds, the inactive threads asynchronpusly transfer the next tile from the global memory and by the time the computation is done, the next tiles should be ready to use. Thus we can basically overlap transfer of tiles from global memory to shared memory with actual matrix multiplication computations.
In the above kernel, we define shared memory matrices of size 4x32x32. For each output element, initally we issue asynchronous copy command from global memory to shared memory of 4 tiles (or stages). The producer pushes the 4 stages into the pipeline. This operation is non-blocking and it does not use registers during the copy process (during standard copy of global to shared, first the data is read into registers and then copied from registers to shared memory).
Next we check in a for-loop if at-least 1 stage has been completed (in FIFO order the first stage to be pushed is the first stage to complete). If not the consumer waits, else pulls the completed stage off the front of the pipeline and does the matrix multiplication of the 2 shared memory matrices corresponding to 1st stage. Now if there are any pending tiles, the producer again issues a asynchronous copy command and pushes this stage to the back of the pipeline. The loop continues until there are no more tiles.
Since data transfer is a time consuming operation as compared to matrix multiplication, thus we issue multiple asynchronous copy commands at the beginning so that there is a good overlap between data transfer and actual computation.
Note that the pipeline object is local to the thread (cuda::pipeline<cuda::thread_scope_thread>) because we are using a single pipeline to queue all the tiles required for computing a single output element by an individual thread. Having the pipeline visiblity at the block level, one cannot use the cuda::pipeline_consumer_wait_prior<pending_batches>(pipeline) command because the completed stage may come from any thread’s job i.e. it could correspond to any other output element.
Time taken to multiply two 4096x4096 matrices is around 14.9248 ms.
Kernel 6 - 2D Tiling + Asynchronous Pipelining Warp Specialization
#define TILE_WIDTH 32
#define COARSE_FACTOR_2D 4
#define NUM_STAGES_ASYNC_PIPELINE 4
__global__
void gemm_fp32_cuda_tiled_2D_async_warp_spl(
const float *a_fp32,
const float *b_fp32,
float *c_fp32,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
auto block = cooperative_groups::this_thread_block();
__shared__ cuda::pipeline_shared_state<cuda::thread_scope_block, NUM_STAGES_ASYNC_PIPELINE> shared_state;
cuda::pipeline<cuda::thread_scope_block> pipe = cuda::make_pipeline(block, &shared_state, 32);
__shared__ alignas(16) float Mds[NUM_STAGES_ASYNC_PIPELINE][TILE_WIDTH*TILE_WIDTH];
__shared__ alignas(16) float Nds[NUM_STAGES_ASYNC_PIPELINE][TILE_WIDTH*TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row_start = by*TILE_WIDTH*COARSE_FACTOR_2D + ty;
int col_start = bx*TILE_WIDTH*COARSE_FACTOR_2D + tx*4;
int tid = block.thread_rank();
int warp_id = tid/32;
for (int r = 0; r < COARSE_FACTOR_2D; r++) {
int row = row_start + r*TILE_WIDTH;
for (int c = 0; c < COARSE_FACTOR_2D; c++) {
int col = col_start + c*TILE_WIDTH;
if (warp_id == 0) {
int row_off = by*TILE_WIDTH*COARSE_FACTOR_2D + r*TILE_WIDTH + tid;
int col_off = bx*TILE_WIDTH*COARSE_FACTOR_2D + c*TILE_WIDTH;
for (int ph = 0; ph < k; ph += TILE_WIDTH) {
int stage = (ph/TILE_WIDTH) % NUM_STAGES_ASYNC_PIPELINE;
pipe.producer_acquire();
cuda::memcpy_async(Mds[stage] + tid*TILE_WIDTH, a_fp32 + row_off*k + ph, cuda::aligned_size_t<4>(sizeof(float)*32), pipe);
cuda::memcpy_async(Nds[stage] + tid*TILE_WIDTH, b_fp32 + (ph + tid)*n + col_off, cuda::aligned_size_t<4>(sizeof(float)*32), pipe);
pipe.producer_commit();
}
}
else {
auto consumer_group = cooperative_groups::tiled_partition<32>(block);
float res[8] = {0.0f};
for (int ph = 0; ph < k; ph += TILE_WIDTH) {
int stage = (ph/TILE_WIDTH) % NUM_STAGES_ASYNC_PIPELINE;
pipe.consumer_wait();
for (int row_off=ty-4; row_off < TILE_WIDTH; row_off += 28) {
for (int i = 0; i < TILE_WIDTH; i++) {
res[4*(row_off/28) + 0] += Mds[stage][row_off*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+0];
res[4*(row_off/28) + 1] += Mds[stage][row_off*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+1];
res[4*(row_off/28) + 2] += Mds[stage][row_off*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+2];
res[4*(row_off/28) + 3] += Mds[stage][row_off*TILE_WIDTH+i]*Nds[stage][i*TILE_WIDTH+tx*4+3];
}
}
cooperative_groups::sync(consumer_group);
pipe.consumer_release();
}
for (int row_off=ty-4; row_off < TILE_WIDTH; row_off += 28) {
c_fp32[(row+row_off-ty)*n+col + 0] = alpha * res[4*(row_off/28) + 0] + beta * c_fp32[(row+row_off-ty)*n+col + 0];
c_fp32[(row+row_off-ty)*n+col + 1] = alpha * res[4*(row_off/28) + 1] + beta * c_fp32[(row+row_off-ty)*n+col + 1];
c_fp32[(row+row_off-ty)*n+col + 2] = alpha * res[4*(row_off/28) + 2] + beta * c_fp32[(row+row_off-ty)*n+col + 2];
c_fp32[(row+row_off-ty)*n+col + 3] = alpha * res[4*(row_off/28) + 3] + beta * c_fp32[(row+row_off-ty)*n+col + 3];
}
}
}
}
}
float *c_gpu_fp32_tiled_2d_async_warp_spl;
cudaErrCheck(cudaMallocManaged(&c_gpu_fp32_tiled_2d_async_warp_spl, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_fp32_tiled_2d_async_warp_spl[i] = 0.0f;
dim3 bd22(8, 32, 1);
dim3 gd22((n+32*COARSE_FACTOR_2D-1)/(32*COARSE_FACTOR_2D), (m+32*COARSE_FACTOR_2D-1)/(32*COARSE_FACTOR_2D), 1);
gemm_fp32_cuda_tiled_2D_async_warp_spl<<<gd22, bd22>>>(a_fp32, b_fp32, c_gpu_fp32_tiled_2d_async_warp_spl, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_fp32_tiled_2d_async_warp_spl));
In the previous kernel, all the threads are participating for both data transfer and actual computations. In this kernel, we divide the responsibilities. Assuming a block of thread of 8x32=256 threads, it will be divided up into warps of 32 threads each. Thus, there will be 8 warps in total per block. We can use the 1st warp (producer) for all data transfer jobs whereas the remaining 7 warps (consumers) would be used for actual matrix multiplcation computations.
Without warp specialization, we can face the following challenges:
Warp Divergence
Some threads in a warp might be doing matrix multiplications whereas the other threads of the same warp might be involved in data transfer from global memory. One cannot achive full SIMD with this kind of setting. Warp specialization aims for full SIMD and removes warp divergence because all threads in warp are either doing data transefr or doing matmul.
Redundant register usage
All threads in a warp use the same number of registers. Clearly the threads involved in matmul needs to use more number of registers than the threads doing data transfer but since threads do not have a separation of responsibilities, all threads are using additional registers.
Unnecessary __syncthreads()
Using __syncthreads() to sync all threads is slow. Since we do not know which threads are doing data transfer and which matmul, we need to do __syncthreads() to sync all threads in a block. This could lead to wastage of bandwidth. On the other hand, with warp specialization, since we know which warps are doing matmul, we can explicitly sync only those warps using cooperative_groups::sync(consumer_group).
Note that the pipeline is shared among all threads in the block unlike the previous kernel where the pipeline had visibility at the thread scope level because with warp specialization, all consumer warps needs to synchronize.
In the above kernel it might appear that the producer warp (warp_id=0) might overwrite the stages as it loops over the k-dimension because there are only 4 stages. Note that the pipeline has been created with shared_state with a maximum concurrency of 4 i.e. at any given point in time the pipeline can have a maximum of 4 stages in the queue. The consumer warps are waiting on the stages. So once 1st stage has been completed for e.g. stage=0 is pushed to pipeline by the producer warp and data is transferred, it is locked for writing until the consumer warps read it and releases the lock.
Time taken to multiply two 4096x4096 matrices is around 21.3606 ms.
It is surprising to see that warp specialization takes more time as compared to N-stage asynchronous pipeline above. It could be due to multiple reasons.
shared_state overhead
Maintaining the shared_state buffer in shared memory by both the producer and consumer warps could be additional overhead as it requires frequent updates once producer pushes a stage or consumer consumes a stage. shared_state was absent in the previous kernel as the pipeline was local to each thread.
Uneven speed of producer and consumer
It could be that the consumer warps are slow to process the computations and the producer warp is waiting to push new stage or vice versa where the producer warp is slow in fetching data from global memory while consumer warps have finished the operations and waiting for new stages in the pipeline.
Kernel 7 - WMMA
#define WMMA_M 16
#define WMMA_N 16
#define WMMA_K 16
__global__
void gemm_wmma(
const half *a,
const half *b,
float *c,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
int lda = k;
int ldb = n;
int ldc = n;
int warpM = (blockIdx.y * blockDim.y + threadIdx.y);
int warpN = (blockIdx.x * blockDim.x + threadIdx.x) / 32;
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> c_frag;
wmma::fill_fragment(acc_frag, 0.0f);
for (int i = 0; i < k; i += WMMA_K) {
int aRow = warpM * WMMA_M;
int aCol = i;
int bRow = i;
int bCol = warpN * WMMA_N;
if (aRow < m && aCol < k && bRow < k && bCol < n) {
wmma::load_matrix_sync(a_frag, a + aRow * lda + aCol, lda);
wmma::load_matrix_sync(b_frag, b + bRow * ldb + bCol, ldb);
wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag);
}
}
int cRow = warpM * WMMA_M;
int cCol = warpN * WMMA_N;
if (cRow < m && cCol < n) {
wmma::load_matrix_sync(c_frag, c + cRow * ldc + cCol, ldc, wmma::mem_row_major);
#pragma unroll
for(int i=0; i < c_frag.num_elements; i++) c_frag.x[i] = alpha * acc_frag.x[i] + beta * c_frag.x[i];
wmma::store_matrix_sync(c + cRow * ldc + cCol, c_frag, ldc, wmma::mem_row_major);
}
}
float *c_gpu_fp32_wmma;
cudaErrCheck(cudaMallocManaged(&c_gpu_fp32_wmma, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_fp32_wmma[i] = 0.0f;
dim3 bd4(128, 4, 1);
dim3 gd4((n+WMMA_N*128/32-1)/(WMMA_N*128/32), (m+WMMA_M*4-1)/(WMMA_M*4), 1);
gemm_wmma<<<gd4, bd4>>>(a_fp16, b_fp16, c_gpu_fp32_wmma, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_fp32_wmma));
Till now we have been doing GEMM operations on the CUDA cores. From this kernel onwards we are going to leverage Tensor Cores for doing GEMM operations. Tensor Cores offers a lot of performance advantage over CUDA cores with regards to GEMM operations.
FP16/BF16, FP8 and INT8 mixed precision training
CUDA cores is only capable of doing FP32 or 32-bit floating point operations in GEMM. Whereas Tensor Cores are capable of doing GEMM with reduced precision such as 16-bit and 8-bit.
More TFLOPS as compared to CUDA cores
In L4 GPU, number of tensor cores are 240 as compared to 7424 CUDA cores but Tensor Cores offer higher peak TFLOPs of 120 as compared to only 30.3 TFLOPs for CUDA cores on 32-bit floats. With 16-bit floats, Tensor Cores offers 242 peak TFLOPs. Tensor Cores can do FMA (Fused Multiply and Add) operations on 4x4 matrices in a single cycle wherease CUDA cores takes multiple cycles for the same.
In the above kernel, we are declaring warp level fragments a_frag, b_frag, c_frag and acc_frag. Each fragment is of shape 16x16 and a_frag and b_frag are of type half which is FP16 data type (16-bit floats) whereas c_frag and acc_frag are of type FP32.
Each block comprises of 512 threads with 128 threads in each of 4 rows. Each row of 128 threads is divided up into 4 warps each of 32 threads. Thus each block comprises of 4x4=16 warps.
Each warp computes a 16x16 tile in the output matrix. Thus with 4x4 warps, each block computes 64x64 tile in the output matrix.
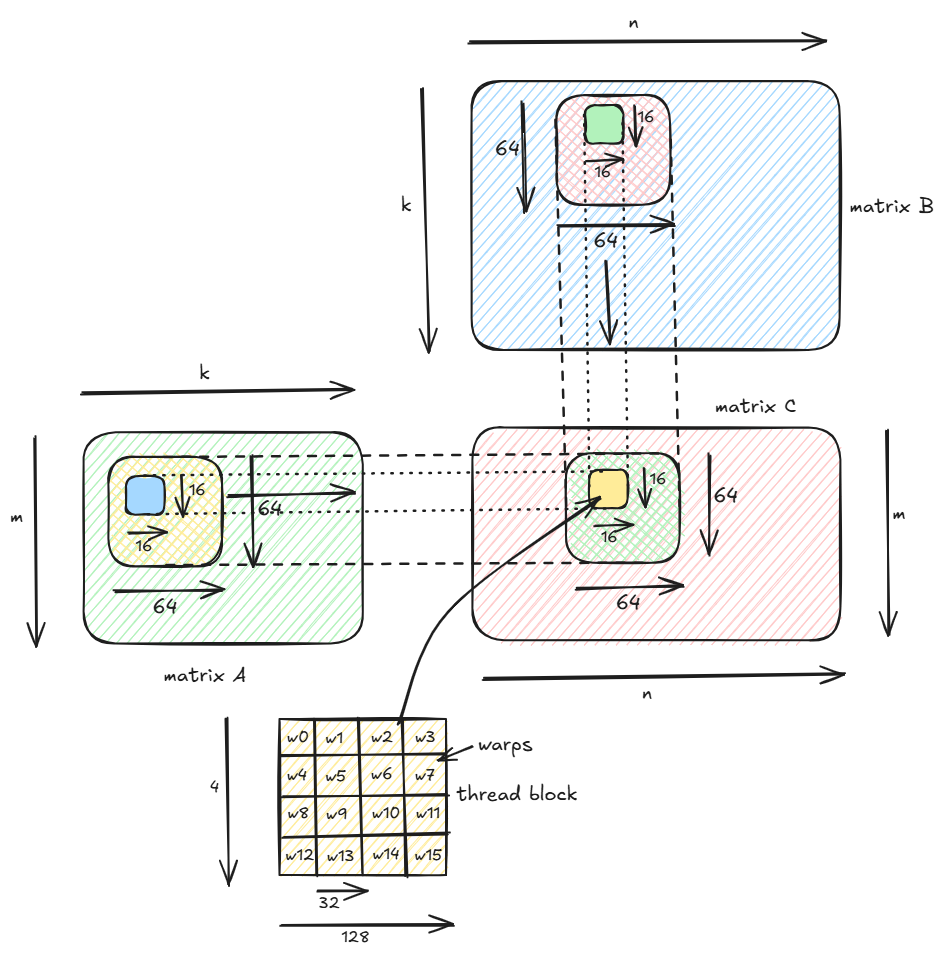
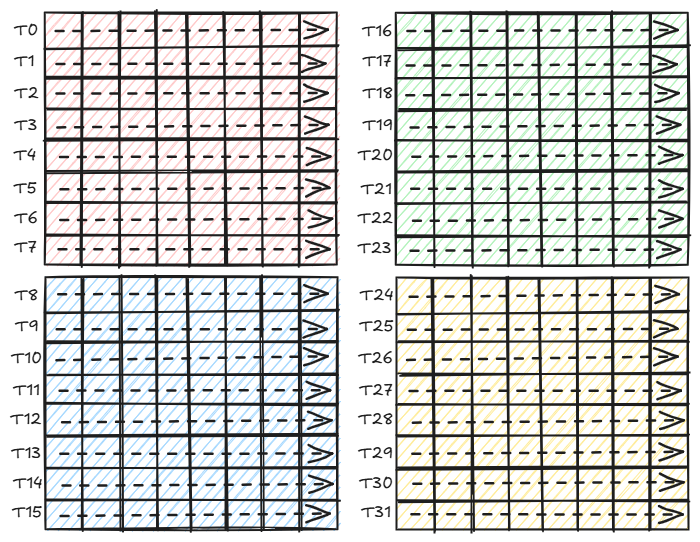
Each warp copies a 16x16 tile from matrix A in global memory into a_frag register and a 16x16 tile from matrix B into b_frag repeated along the k-dimension using wmma::load_matrix_sync command. Since a warp contains 32 threads thus to copy 16x16=256 elements each thread copies 8 elements from global memory to the fragments in registers.
Thread 0 loads 8 FP16 elements from 1st row and 1st col.
Thread 1 loads 8 FP16 elements from 2nd row and 1st col.
...
Thread 15 loads 8 FP16 elements from 16th row and 1st col.
Thread 16 loads 8 FP16 elements from 1st row and 8th col.
Thread 17 loads 8 FP16 elements from 2nd row and 9th col.
...
Thread 31 loads 8 FP16 elements from 16th row and 8th col.
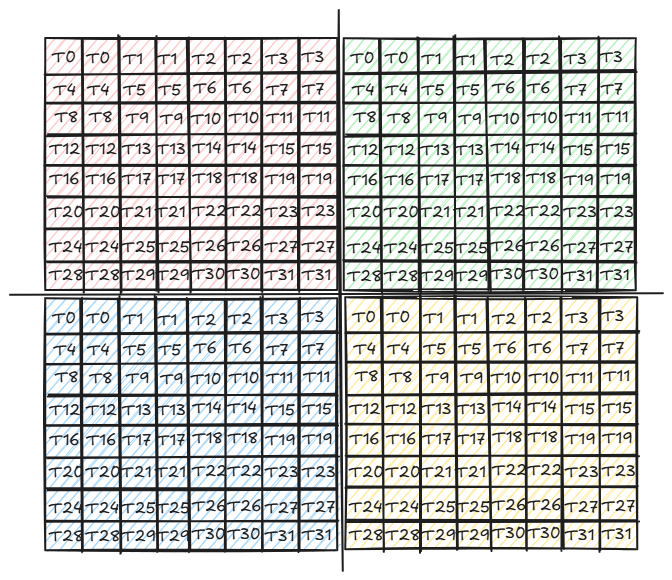
Next wmma::mma_sync command multiplies the 16x16 tile in a_frag with a 16x8 tile in b_frag repeated 2 times horizontally (because b_frag is 16x16) using Tensor Cores. The results of the matmul operations are stored in acc_frag. Tensor Cores does FMA (Fused Multiply and Add) operation on the fragments.
The 16x16 output tile is divided into 4 8x8 tiles and per 8x8 of 16-bit elements, each thread in a warp computes 32-bits or 2 consecutive elements as shown below.
Once a warp is done with multiplying 16x16 fragments, the results of the acc_frag is updated to c_frag. Since it is a GEMM operation where we are computing D = alpha * AxB + beta * C, the results of AxB are stored in acc_frag, and instead of using two separate matrices C and D, we are updating the matrix C itself with the final result assuming that the original matrix C is not used later. Once we update the c_frag with elementwise multiplication and summation, we update the results in the output matrix C in global memory.
In the event we do not want GEMM but only say the product AxB, we can just do wmma::store_matrix_sync(c + cRow * ldc + cCol, acc_frag, ldc, wmma::mem_row_major).
Time taken to multiply two 4096x4096 matrices is around 14.7231 ms.
A slightly better solution would be to first copy the 64x64 tile of FP16 floats from global memory to shared memory and then use wmma::load_matrix_sync to transfer data from shared memory to registers for each 16x16 sub-tile within the 64x64 tile. Since copying from global memory to shared memory also involves register, we can use async copy (which does not use registers) as previously seen.
__global__
void gemm_wmma_shmm(
const half *a,
const half *b,
float *c,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
cuda::pipeline<cuda::thread_scope_thread> pipeline = cuda::make_pipeline();
__shared__ alignas(16) half Mds[NUM_STAGES_ASYNC_PIPELINE][TILE_WIDTH_WMMA*TILE_WIDTH_WMMA];
__shared__ alignas(16) half Nds[NUM_STAGES_ASYNC_PIPELINE][TILE_WIDTH_WMMA*TILE_WIDTH_WMMA];
int ldc = n;
int warpM = (blockIdx.y * blockDim.y + threadIdx.y);
int warpN = (blockIdx.x * blockDim.x + threadIdx.x) / 32;
int bx = blockIdx.x;
int by = blockIdx.y;
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> c_frag;
wmma::fill_fragment(acc_frag, 0.0f);
int idx = threadIdx.y * blockDim.x + threadIdx.x;
int a_block_row = by * TILE_WIDTH_WMMA;
int b_block_col = bx * TILE_WIDTH_WMMA;
for (int s = 0; s < NUM_STAGES_ASYNC_PIPELINE; s++) {
int h = s*TILE_WIDTH_WMMA;
pipeline.producer_acquire();
#pragma unroll
for (int j = idx; j < TILE_WIDTH_WMMA*TILE_WIDTH_WMMA; j += blockDim.x * blockDim.y) {
cuda::memcpy_async(Mds[s] + j, a + (a_block_row + j/TILE_WIDTH_WMMA)*k + h + (j % TILE_WIDTH_WMMA), cuda::aligned_size_t<2>(sizeof(half)), pipeline);
cuda::memcpy_async(Nds[s] + j, b + (h + j/TILE_WIDTH_WMMA)*n + b_block_col + (j % TILE_WIDTH_WMMA), cuda::aligned_size_t<2>(sizeof(half)), pipeline);
}
pipeline.producer_commit();
}
int s = NUM_STAGES_ASYNC_PIPELINE;
for (int i = 0; i < k; i += TILE_WIDTH_WMMA) {
int stage = s % NUM_STAGES_ASYNC_PIPELINE;
constexpr size_t pending_batches = NUM_STAGES_ASYNC_PIPELINE - 1;
cuda::pipeline_consumer_wait_prior<pending_batches>(pipeline);
__syncthreads();
#pragma unroll
for (int j = 0; j < TILE_WIDTH_WMMA; j += WMMA_K) {
int a_warp_row = threadIdx.y * WMMA_M;
int a_warp_col = j;
int b_warp_row = j;
int b_warp_col = (threadIdx.x / 32) * WMMA_N;
if (a_warp_row < TILE_WIDTH_WMMA && a_warp_col < TILE_WIDTH_WMMA && b_warp_row < TILE_WIDTH_WMMA && b_warp_col < TILE_WIDTH_WMMA) {
wmma::load_matrix_sync(a_frag, Mds[stage] + a_warp_row * TILE_WIDTH_WMMA + a_warp_col, TILE_WIDTH_WMMA);
wmma::load_matrix_sync(b_frag, Nds[stage] + b_warp_row * TILE_WIDTH_WMMA + b_warp_col, TILE_WIDTH_WMMA);
wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag);
}
}
pipeline.consumer_release();
__syncthreads();
pipeline.producer_acquire();
int h = s*TILE_WIDTH_WMMA;
if (h < k) {
#pragma unroll
for (int j = idx; j < TILE_WIDTH_WMMA*TILE_WIDTH_WMMA; j += blockDim.x * blockDim.y) {
cuda::memcpy_async(Mds[stage] + j, a + (a_block_row + j/TILE_WIDTH_WMMA)*k + h + (j % TILE_WIDTH_WMMA), cuda::aligned_size_t<2>(sizeof(half)), pipeline);
cuda::memcpy_async(Nds[stage] + j, b + (h + j/TILE_WIDTH_WMMA)*n + b_block_col + (j % TILE_WIDTH_WMMA), cuda::aligned_size_t<2>(sizeof(half)), pipeline);
}
}
pipeline.producer_commit();
s += 1;
}
int cRow = warpM * WMMA_M;
int cCol = warpN * WMMA_N;
if (cRow < m && cCol < n) {
wmma::load_matrix_sync(c_frag, c + cRow * ldc + cCol, ldc, wmma::mem_row_major);
#pragma unroll
for(int i=0; i < c_frag.num_elements; i++) c_frag.x[i] = alpha * acc_frag.x[i] + beta * c_frag.x[i];
wmma::store_matrix_sync(c + cRow * ldc + cCol, c_frag, ldc, wmma::mem_row_major);
}
}
Time taken to multiply two 4096x4096 matrices is around 14.1765 ms. This is slightly better than the previous kernel.
Kernel 8 - mma.sync custom
__global__
void gemm_mma_sync_fp16(
const half *a,
const half *b,
float *c,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
__shared__ alignas(16) half Mds[TILE_WIDTH_WMMA*TILE_WIDTH_WMMA];
__shared__ alignas(16) half Nds[TILE_WIDTH_WMMA*TILE_WIDTH_WMMA];
int idx = threadIdx.y * blockDim.x + threadIdx.x;
int warp_row_id = idx/blockDim.x;
int warp_col_id = (idx % blockDim.x)/32;
int thread_id_in_warp = idx % 32;
for (int i = 0; i < k; i += TILE_WIDTH_WMMA) {
int a_row = blockIdx.y * TILE_WIDTH_WMMA;
int a_col = i;
for (int j = idx; j < TILE_WIDTH_WMMA*TILE_WIDTH_WMMA; j += blockDim.x * blockDim.y) {
Mds[j] = a[(a_row + j/TILE_WIDTH_WMMA) * k + (a_col + j % TILE_WIDTH_WMMA)];
}
int b_row = i;
int b_col = blockIdx.x * TILE_WIDTH_WMMA;
for (int j = idx; j < TILE_WIDTH_WMMA*TILE_WIDTH_WMMA; j += blockDim.x * blockDim.y) {
Nds[j] = b[(b_row + j/TILE_WIDTH_WMMA) * n + (b_col + j % TILE_WIDTH_WMMA)];
}
__syncthreads();
for (int j = 0; j < TILE_WIDTH_WMMA; j += 16) {
uint32_t regs_a[4];
uint32_t regs_b_1[2];
uint32_t regs_b_2[2];
float regs_c_1[4] = {0.0f};
float regs_c_2[4] = {0.0f};
int m_row = warp_row_id * 16;
int m_col = j;
int n_row = j;
int n_col_1 = warp_col_id * 16;
int n_col_2 = n_col_1 + 8;
uint32_t addr_a = __cvta_generic_to_shared(&Mds[(m_row + thread_id_in_warp % 16) * TILE_WIDTH_WMMA + (thread_id_in_warp/16) * 8 + m_col]);
uint32_t addr_b_1 = __cvta_generic_to_shared(&Nds[(n_row + thread_id_in_warp % 16) * TILE_WIDTH_WMMA + n_col_1]);
uint32_t addr_b_2 = __cvta_generic_to_shared(&Nds[(n_row + thread_id_in_warp % 16) * TILE_WIDTH_WMMA + n_col_2]);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x4.shared.b16 "
"{%0, %1, %2, %3}, [%4];"
: "=r"(regs_a[0]), "=r"(regs_a[1]), "=r"(regs_a[2]), "=r"(regs_a[3])
: "r"(addr_a)
);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.shared.trans.b16 "
"{%0, %1}, [%2];"
: "=r"(regs_b_1[0]), "=r"(regs_b_1[1])
: "r"(addr_b_1)
);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.shared.trans.b16 "
"{%0, %1}, [%2];"
: "=r"(regs_b_2[0]), "=r"(regs_b_2[1])
: "r"(addr_b_2)
);
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3}, "
"{%4, %5, %6, %7}, "
"{%8, %9}, "
"{%0, %1, %2, %3};\n"
: "+f"(regs_c_1[0]), "+f"(regs_c_1[1]), "+f"(regs_c_1[2]),"+f"(regs_c_1[3])
: "r"(regs_a[0]), "r"(regs_a[1]), "r"(regs_a[2]), "r"(regs_a[3]), "r"(regs_b_1[0]), "r"(regs_b_1[1])
);
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3}, "
"{%4, %5, %6, %7}, "
"{%8, %9}, "
"{%0, %1, %2, %3};\n"
: "+f"(regs_c_2[0]), "+f"(regs_c_2[1]), "+f"(regs_c_2[2]),"+f"(regs_c_2[3])
: "r"(regs_a[0]), "r"(regs_a[1]), "r"(regs_a[2]), "r"(regs_a[3]), "r"(regs_b_2[0]), "r"(regs_b_2[1])
);
#pragma unroll
for (int q = 0; q < 4; q++) {
int rw = (thread_id_in_warp >> 2) + 8 * (q / 2);
int cl = 2 * (thread_id_in_warp % 4) + (q % 2);
c[(a_row + m_row + rw) * n + (b_col + n_col_1 + cl)] += regs_c_1[q];
c[(a_row + m_row + rw) * n + (b_col + n_col_2 + cl)] += regs_c_2[q];
}
}
__syncthreads();
}
}
float *c_gpu_mma_sync_fp16;
cudaErrCheck(cudaMallocManaged(&c_gpu_mma_sync_fp16, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_mma_sync_fp16[i] = 0.0f;
dim3 bd6(128, 4, 1);
dim3 gd6((n+TILE_WIDTH_WMMA-1)/TILE_WIDTH_WMMA, (m+TILE_WIDTH_WMMA-1)/TILE_WIDTH_WMMA, 1);
gemm_mma_sync_fp16<<<gd6, bd6>>>(a_fp16, b_fp16, c_gpu_mma_sync_fp16, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_mma_sync_fp16));
In this kernel we show how to write the Tensor Core GEMM without using WMMA. The crucial parts of understanding the above kernel is understanding how ldmatrix PTX instruction is used to copy from shared memory to registers. For e.g. the instruction ldmatrix.sync.aligned.m8n8.x4.shared.b16 is used to copy 4 8x8 submatrices of 16-bit data types from shared memory to registers. We saw this earlier with WMMA too where the 16x16 a_frag was divided up into 4 8x8 sub-tiles and each thread in a warp then copies 8 FP16 elements.
The next crucial part is how to make the PTX instruction for mma.sync. For e.g. mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 does matrix-multiply-and-add operation on a 16x16 matrix A and 16x8 matrix B where A is row-major and B is column major. A and B are both FP16 and output matrix is FP32.
Each block of thread is divided into 4x4 warps where each warp computes 16x16 sub-matrix of the output. Given an output matrix of shape 1024x1024, each block computes a 64x64 submatrix. In the earlier kernels, we would directly compute the 64x64 output tile by sliding horizontally across A and vertically across B and loading 64x64 tiles from global to shared memory and doing matmul on each tile and summing up the results across the tiles. In this kernel, we further divide each 64x64 tile into 16x16 sub-tiles which are handled by warps because we want to leverage the Tensor Cores.
A warp or a group of 32 threads loads the 16x16 sub-tile from shared memory to registers as seen above.
Each 8 FP16 elements is read into 4 FP32 registers using ldmatrix.sync.aligned.m8n8.x4.shared.b16
asm volatile(
"ldmatrix.sync.aligned.m8n8.x4.shared.b16 "
"{%0, %1, %2, %3}, [%4];"
: "=r"(regs_a[0]), "=r"(regs_a[1]), "=r"(regs_a[2]), "=r"(regs_a[3])
: "r"(addr_a)
);
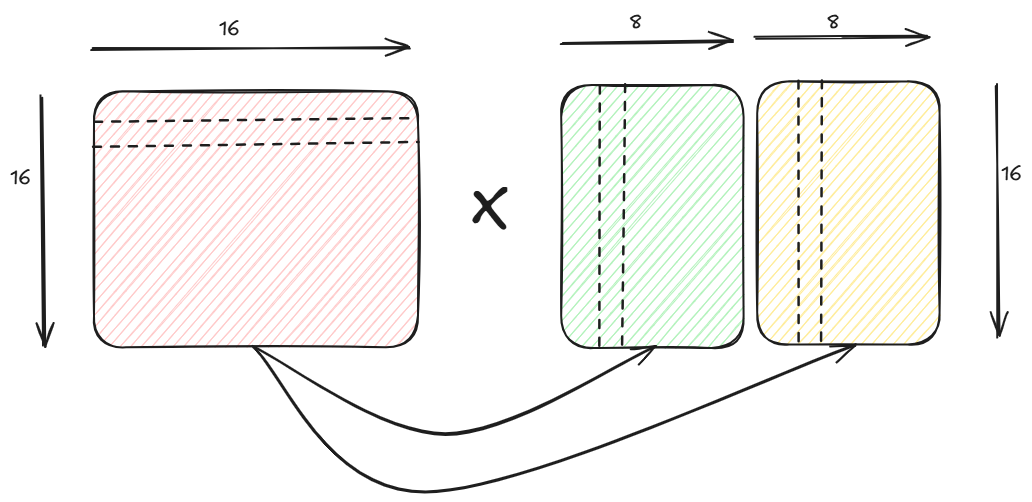
Note that since mma.sync can only multiply a 16x16 matrix with a 16x8 matrix at a time, so we do 2 mma.sync operations each multiplying a 16x16 matrix with a 16x8 matrix and then merging the results.
Finally we update the output matrix C with the final results. Note that I am directly updating the C matrix in the global memory. A better approach here would be to use stmatrix.sync to write the output 16x16 matrix from registers to shared memory and then from shared memory to global memory.
Note the thread id to index mapping corresponding to each 16x8 matrix. Since a warp of 32 threads computes 128 FP32 elements in the output, thus each thread computes 4 elements. Hence each reg_c_1 and regs_c_2 is an array of 4 elements. The 4 indices in the 16x8 matrix corresponding to each thread id is computed as follows.
Thread 0 computes elements (0,0) (0,1) (8,0) and (8,1) for a 16x8 output submatrix.
Thread 1 computes elements (0,2) (0,3) (8,2) and (8,3) for a 16x8 output submatrix.
...
Thread 31 computes elements (7,6) (7,7) (15,6) and (15,7) for a 16x8 output submatrix.
For thread id tid and element index q (where q ranges from 0 to 3), then we have:
row(tid, q) = (tid >> 2) + 8 * (q / 2)
col(tid, q) = 2 * (tid % 4) + (q % 2)
For e.g. for tid=31
row(tid,0)=7 col(tid,0)=6
row(tid,1)=7 col(tid,1)=7
row(tid,2)=15 col(tid,2)=6
row(tid,3)=15 col(tid,3)=7
Note that instead of ldmatrix to load the matrix from shared memory to registers, one can also directly use the thread id to index mapping corresponding to the shared memory matrices Mds and Nds similar to how we are using for the output matrix. But ldmatrix is usually faster.
Time taken to multiply two 4096x4096 matrices is around 27.6931 ms.
The performance significantly improves if instead of each warp computing a 16x16 sub-tile in the output, each warp computes a 2D tile of 8x8 tiles each of 16x16 values i.e. each warp computes 128x128 tile in the output and thus each block of 2x2 warps computes 256x256 tile in the output as follows:
__global__
void gemm_mma_sync_fp16_2d_tiled(
half *a,
half *b,
float *c,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
__shared__ alignas(16) half Mds[32*32];
__shared__ alignas(16) half Nds[32*32];
int idx = threadIdx.y * blockDim.x + threadIdx.x;
int warp_row_id = idx/blockDim.x;
int warp_col_id = (idx % blockDim.x)/32;
int thread_id_in_warp = idx % 32;
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 8; j++) {
float regs_c_1[4] = {0.0f};
float regs_c_2[4] = {0.0f};
for (int k1 = 0; k1 < k; k1 += 32) {
int a_row = (8 * blockIdx.y + i) * 32;
int a_col = k1;
int b_row = k1;
int b_col = (8 * blockIdx.x + j) * 32;
#pragma unroll
for (int j1 = idx; j1 < 32*32; j1 += blockDim.x * blockDim.y) {
int row = j1/32;
int col = j1 % 32;
Mds[row*32 + col] = a[(a_row + row) * k + (a_col + col)];
Nds[row*32 + col] = b[(b_row + row) * n + (b_col + col)];
}
__syncthreads();
for (int k2 = 0; k2 < 32; k2 += 16) {
uint32_t regs_a[4];
uint32_t regs_b_1[2];
uint32_t regs_b_2[2];
int m_row = warp_row_id * 16;
int m_col = k2;
int n_row = k2;
int n_col_1 = warp_col_id * 16;
int n_col_2 = n_col_1 + 8;
uint32_t addr_a = __cvta_generic_to_shared(&Mds[(m_row + thread_id_in_warp % 16) * 32 + (thread_id_in_warp/16) * 8 + m_col]);
uint32_t addr_b_1 = __cvta_generic_to_shared(&Nds[(n_row + thread_id_in_warp % 16) * 32 + n_col_1]);
uint32_t addr_b_2 = __cvta_generic_to_shared(&Nds[(n_row + thread_id_in_warp % 16) * 32 + n_col_2]);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x4.shared.b16 "
"{%0, %1, %2, %3}, [%4];"
: "=r"(regs_a[0]), "=r"(regs_a[1]), "=r"(regs_a[2]), "=r"(regs_a[3])
: "r"(addr_a)
);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.shared.trans.b16 "
"{%0, %1}, [%2];"
: "=r"(regs_b_1[0]), "=r"(regs_b_1[1])
: "r"(addr_b_1)
);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.shared.trans.b16 "
"{%0, %1}, [%2];"
: "=r"(regs_b_2[0]), "=r"(regs_b_2[1])
: "r"(addr_b_2)
);
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3}, "
"{%4, %5, %6, %7}, "
"{%8, %9}, "
"{%0, %1, %2, %3};\n"
: "+f"(regs_c_1[0]), "+f"(regs_c_1[1]), "+f"(regs_c_1[2]),"+f"(regs_c_1[3])
: "r"(regs_a[0]), "r"(regs_a[1]), "r"(regs_a[2]), "r"(regs_a[3]), "r"(regs_b_1[0]), "r"(regs_b_1[1])
);
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3}, "
"{%4, %5, %6, %7}, "
"{%8, %9}, "
"{%0, %1, %2, %3};\n"
: "+f"(regs_c_2[0]), "+f"(regs_c_2[1]), "+f"(regs_c_2[2]),"+f"(regs_c_2[3])
: "r"(regs_a[0]), "r"(regs_a[1]), "r"(regs_a[2]), "r"(regs_a[3]), "r"(regs_b_2[0]), "r"(regs_b_2[1])
);
}
__syncthreads();
}
int a_row = (8 * blockIdx.y + i) * 32;
int b_col = (8 * blockIdx.x + j) * 32;
int m_row = warp_row_id * 16;
int n_col_1 = warp_col_id * 16;
int n_col_2 = n_col_1 + 8;
#pragma unroll
for (int q = 0; q < 4; q++) {
int rw = (thread_id_in_warp >> 2) + 8 * (q / 2);
int cl = 2 * (thread_id_in_warp % 4) + (q % 2);
c[(a_row + m_row + rw) * n + (b_col + n_col_1 + cl)] += regs_c_1[q];
c[(a_row + m_row + rw) * n + (b_col + n_col_2 + cl)] += regs_c_2[q];
}
}
}
}
float *c_gpu_mma_sync_fp16_2d_tiled;
cudaErrCheck(cudaMallocManaged(&c_gpu_mma_sync_fp16_2d_tiled, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) c_gpu_mma_sync_fp16_2d_tiled[i] = 0.0f;
dim3 bd7(64, 2, 1);
dim3 gd7((n+256-1)/256, (m+256-1)/256, 1);
gemm_mma_sync_fp16_2d_tiled<<<gd7, bd7>>>(a_fp16, b_fp16, c_gpu_mma_sync_fp16_2d_tiled, 1.0, 0.0, m, n, k);
cudaDeviceSynchronize();
cudaErrCheck(cudaFree(c_gpu_mma_sync_fp16_2d_tiled));
Time taken to multiply two 4096x4096 matrices is around 13.1082 ms
Kernel 9 - mma.sync with swizzling
Before deep diving into this kernel it is important to understand how shared memory bank conflicts affects performance. The shared memory is divided up into memory banks so that multiple threads can concurrently access different memory bank and access is parallelized. Usually shared memory is divided into 32 memory banks meaning that at a time 32 threads can access 32 different memory addresses concurrently. Given a warp also has 32 threads, if all the threads in a warp accesses different memory banks, then in a single cycle one can read upto 32 values from the shared memory. But if two or more threads in the same warp or different warps accesses the same memory bank, then access is serialized for that memory bank and multiple cycles would be required affecting performance.
Each address corresponding to a memory bank is 32-bit i.e. for 16-bit floats the same memory bank can serve 2 FP16 values instead of one FP32.
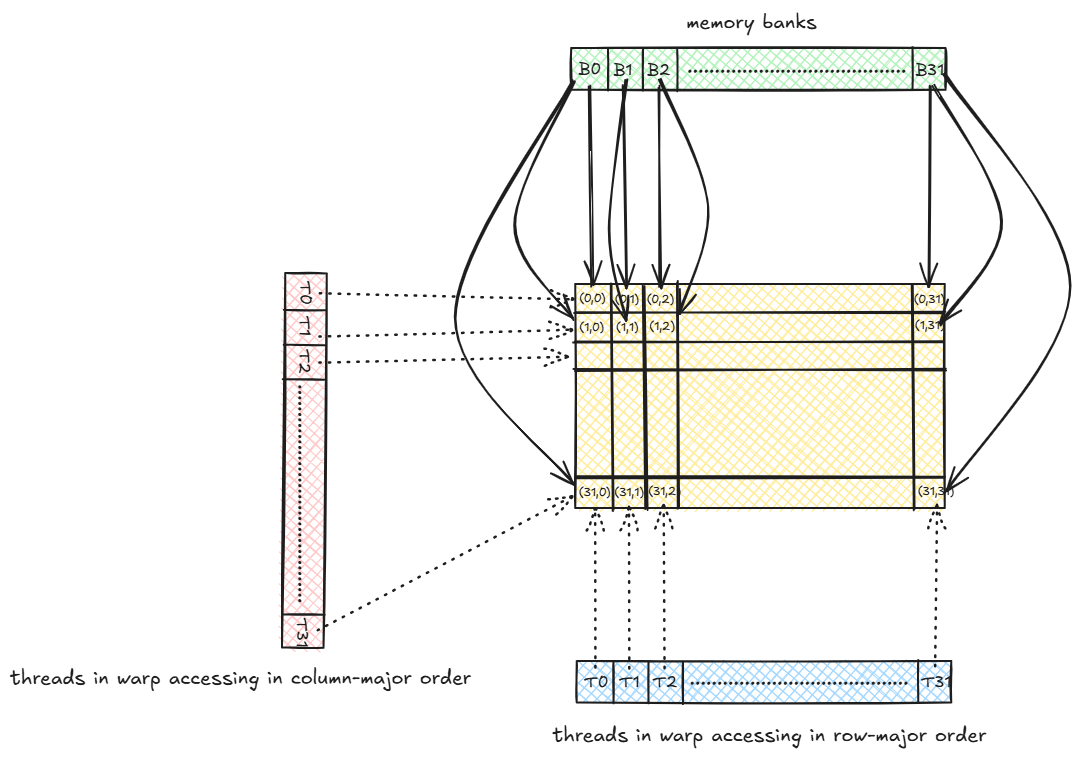
In a row-major layout, consecutive elements in a row of a matrix (FP32) are assigned to consecutive memory banks in a round robin fashion. For e.g. if a matrix is of shape 32x32 then the 1st 32 elements (from 1st row) will be assigned to the 32 memory banks. The next 32 elements (in the next row) would again be assigned to the 32 memory banks and so on. Thus each memory bank serves 32 values. If a warp of 32 threads access 32 elements from shared memory at a time in row-major order, then there will be no memory bank conflict because in the 1st cycle, each thread reads from one bank without conflict, in the next cycle again each thread reads from one bank without conflict and so on.
But if the same warp accesses the elements in a column-major order i.e. T0 accessess (0,0), T1 accessess (1,0), T2 accesses (2,0) and so on, given that (0,0), (1,0), (2,0), ... (31,0) all are assigned to the same memory bank, we see that there is 32-way memory bank conflict. Thus reading each column takes 32 cycles as compared to 1 cycle in row-major order access.
Even if the threads accesses the elements in row-major order, but assuming that each thread accesses 2 consecutive FP32 values from the matrix or each thread accesses with a stride of 2 i.e. Thread Ti accesses element at index (2*i) % 32. For e.g.:
TO accessess (0,0) (memory bank = 0)
T1 accessess (0,2) (memory bank = 2)
...
T15 accessess (0,30) (memory bank = 30)
T16 accessess (1,0) (memory bank = 0)
T17 accessess (1,2) (memory bank = 2)
...
T31 accessess (1,30) (memory bank = 30)
Thus we see that threads Ti and Ti+16 are accessing the same memory bank. Thus each memory bank is accesses by 2 threads and thus a 2-way shared memory bank conflict arises. If each thread accesses 4 elements or with a stride of 4, we would have 4-way conflict and 8-way conflict for 8 elements and so on.
In our ldmatrix.sync instruction above, each thread loads 8 consecutive FP16 values thus each thread accessess 4 consecutive memory banks (each bank is 32-bit) and thus ldmatrix.sync would have 4-way memory bank conflict.
There are 2 ways to handle memory bank conflicts:
Padding
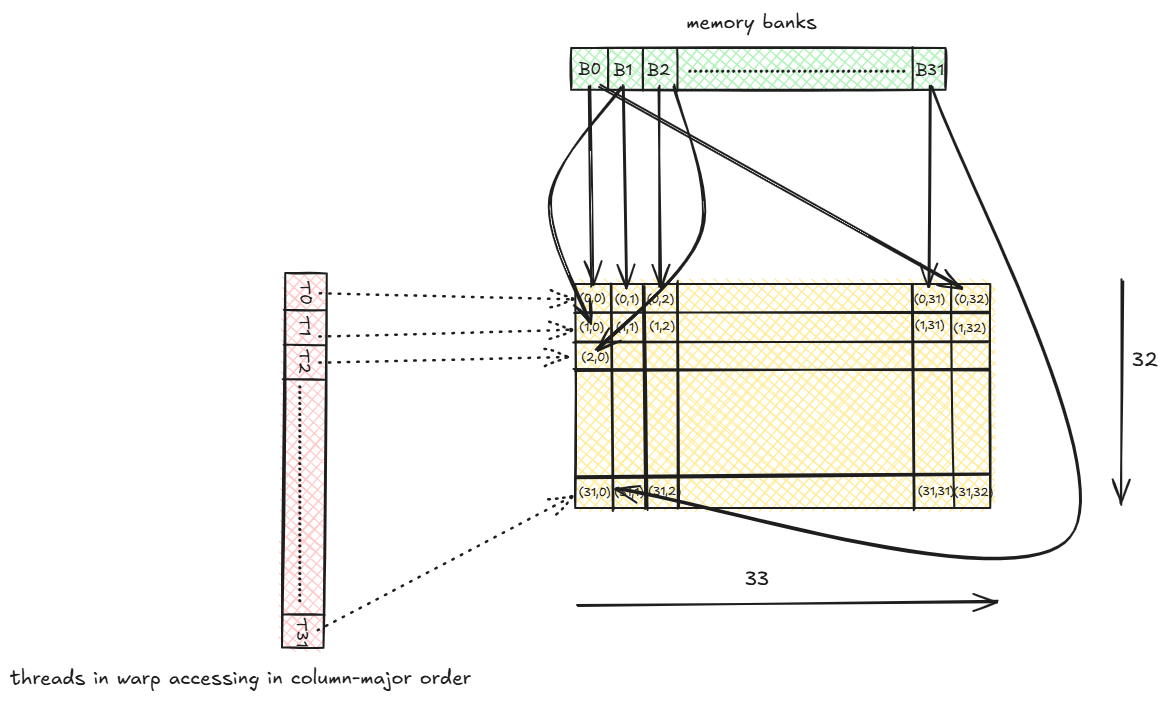
In the column-major access seen above we are facing 32 way memory bank conflict. Now if instead of 32x32 matrix in shared memory we have 32x33 matrix, then note that each thread in a warp acesses a different memory bank per column and we have removed any memory bank conflict. We can use a padding value for the new last column added to prevent memory bank conflicts.
Let’s see if it resolves the 2-way conflict example above.
TO accessess (0,0) (memory bank = 0)
T1 accessess (0,2) (memory bank = 2)
...
T15 accessess (0,30) (memory bank = 30)
T16 accessess (1,0) (memory bank = 1)
T17 accessess (1,2) (memory bank = 3)
...
T31 accessess (1,30) (memory bank = 31)
We see that each thread now accesses a different memory bank. The first 16 threads accesses the even numbered banks while the next 16 threads accesses the odd numbered banks because the last padded column shifts the bank assignment by 1.
Swizzling
In swizzling instead of adding an extra column with a padding value, each (row, col) index is transformed into (row, row^col) where row^col is XOR of row and col. Basically this transformation permutes the values in a row. Depending on how we permute the values, we can avoid shared memory bank conflicts. The exact mathematical proof of why permutation of a row works in solving bank conflicts will be dealt with in the next post.
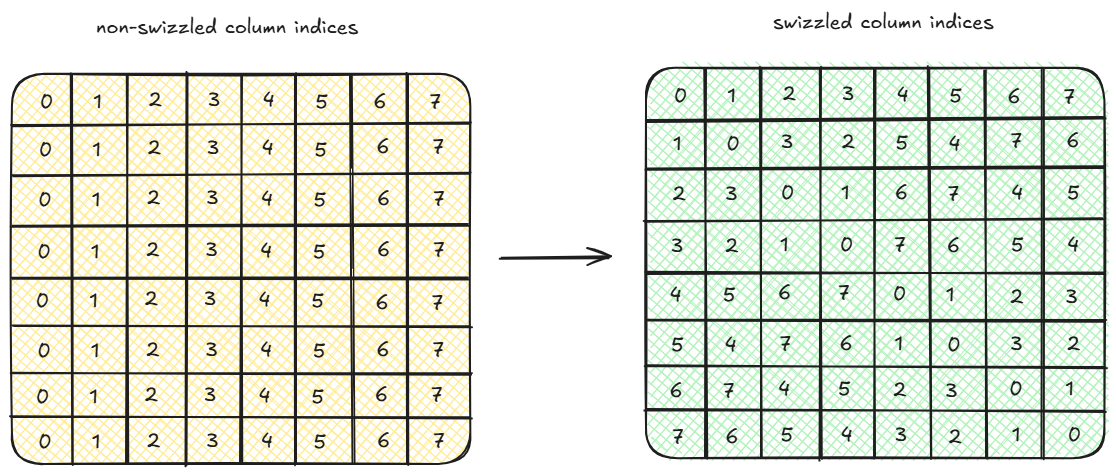
Taking the example of 2-way conflict scenario above, the thread to index assignment looks as follows with swizzling.
TO accessess (0,0^0) = (0,0) (memory bank = 0)
T1 accessess (0,0^2) = (0,2) (memory bank = 2)
...
T15 accessess (0,0^30) = (0,30) (memory bank = 30)
T16 accessess (1,1^0) = (1,1) (memory bank = 1)
T17 accessess (1,1^2) = (1,3) (memory bank = 3)
...
T31 accessess (1,1^30) = (1,31) (memory bank = 31)
As similar to the above solution with padding, the first 16 threads accesses the even numbered banks while the next 16 threads accesses the odd numbered banks. Note that we do not use padding here and the matrix size is still 32x32. Feel free to try this out with multiple rows.
We modify the above mma.sync 2D tiled kernel with swizzling below.
__device__
int get_swizzled_index(int row, int col, int k, int u, int v) {
return (col/k)*k + (v*(((row % k)/u)^((col % k)/v)) + ((col % k) % v)) % k;
}
__global__
void gemm_mma_sync_fp16_2d_tiled_swizzled(
half *a,
half *b,
float *c,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
__shared__ alignas(16) half Mds[32*32];
__shared__ alignas(16) half Nds[32*32];
int idx = threadIdx.y * blockDim.x + threadIdx.x;
int warp_row_id = idx/blockDim.x;
int warp_col_id = (idx % blockDim.x)/32;
int thread_id_in_warp = idx % 32;
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 8; j++) {
float regs_c_1[4] = {0.0f};
float regs_c_2[4] = {0.0f};
for (int k1 = 0; k1 < k; k1 += 32) {
int a_row = (8 * blockIdx.y + i) * 32;
int a_col = k1;
int b_row = k1;
int b_col = (8 * blockIdx.x + j) * 32;
#pragma unroll
for (int j1 = idx; j1 < 32*32; j1 += blockDim.x * blockDim.y) {
int row = j1/32;
int col = j1 % 32;
int s_col = get_swizzled_index(row, col, 32, 2, 8);
Mds[row*32 + s_col] = a[(a_row + row) * k + (a_col + col)];
Nds[row*32 + s_col] = b[(b_row + row) * n + (b_col + col)];
}
__syncthreads();
for (int k2 = 0; k2 < 32; k2 += 16) {
uint32_t regs_a[4];
uint32_t regs_b_1[2];
uint32_t regs_b_2[2];
int m_row = warp_row_id * 16;
int m_col = k2;
int n_row = k2;
int n_col_1 = warp_col_id * 16;
int n_col_2 = n_col_1 + 8;
int x = (thread_id_in_warp/16) * 8 + m_col;
int y = n_col_1;
int z = n_col_2;
x = get_swizzled_index(m_row + thread_id_in_warp % 16, x, 32, 2, 8);
y = get_swizzled_index(n_row + thread_id_in_warp % 16, y, 32, 2, 8);
z = get_swizzled_index(n_row + thread_id_in_warp % 16, z, 32, 2, 8);
uint32_t addr_a = __cvta_generic_to_shared(&Mds[(m_row + thread_id_in_warp % 16) * 32 + x]);
uint32_t addr_b_1 = __cvta_generic_to_shared(&Nds[(n_row + thread_id_in_warp % 16) * 32 + y]);
uint32_t addr_b_2 = __cvta_generic_to_shared(&Nds[(n_row + thread_id_in_warp % 16) * 32 + z]);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x4.shared.b16 "
"{%0, %1, %2, %3}, [%4];"
: "=r"(regs_a[0]), "=r"(regs_a[1]), "=r"(regs_a[2]), "=r"(regs_a[3])
: "r"(addr_a)
);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.shared.trans.b16 "
"{%0, %1}, [%2];"
: "=r"(regs_b_1[0]), "=r"(regs_b_1[1])
: "r"(addr_b_1)
);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.shared.trans.b16 "
"{%0, %1}, [%2];"
: "=r"(regs_b_2[0]), "=r"(regs_b_2[1])
: "r"(addr_b_2)
);
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3}, "
"{%4, %5, %6, %7}, "
"{%8, %9}, "
"{%0, %1, %2, %3};\n"
: "+f"(regs_c_1[0]), "+f"(regs_c_1[1]), "+f"(regs_c_1[2]),"+f"(regs_c_1[3])
: "r"(regs_a[0]), "r"(regs_a[1]), "r"(regs_a[2]), "r"(regs_a[3]), "r"(regs_b_1[0]), "r"(regs_b_1[1])
);
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3}, "
"{%4, %5, %6, %7}, "
"{%8, %9}, "
"{%0, %1, %2, %3};\n"
: "+f"(regs_c_2[0]), "+f"(regs_c_2[1]), "+f"(regs_c_2[2]),"+f"(regs_c_2[3])
: "r"(regs_a[0]), "r"(regs_a[1]), "r"(regs_a[2]), "r"(regs_a[3]), "r"(regs_b_2[0]), "r"(regs_b_2[1])
);
}
__syncthreads();
}
int a_row = (8 * blockIdx.y + i) * 32;
int b_col = (8 * blockIdx.x + j) * 32;
int m_row = warp_row_id * 16;
int n_col_1 = warp_col_id * 16;
int n_col_2 = n_col_1 + 8;
#pragma unroll
for (int q = 0; q < 4; q++) {
int rw = (thread_id_in_warp >> 2) + 8 * (q / 2);
int cl = 2 * (thread_id_in_warp % 4) + (q % 2);
c[(a_row + m_row + rw) * n + (b_col + n_col_1 + cl)] += regs_c_1[q];
c[(a_row + m_row + rw) * n + (b_col + n_col_2 + cl)] += regs_c_2[q];
}
}
}
}
Let’s try to understand how we compute the swizzled indices in the __device__ kernel get_swizzled_index.
As seen earlier, when ldmatrix.sync is used to copy from shared memory to registers, each thread in a warp copies 8 consecutive FP16 values. Each shared memory matrix Mds and Nds is of shape 32x32. A block of 2x2 warps loads from 32x32 Mds and Nds matrices since each warp loads 16x16 sub-tile. Since each element is FP16 thus 2 consecutive elements in Mds/Nds are assigned to same memory bank and as a result, all threads accessing the 1st two rows of Mds/Nds do not have conflicts but threads in every alternate row have bank conflicts with each other.
If we look at only warp 0 i.e. warp loading the 1st 16x16 sub-tile.
Warp (0,0)
T0 loads (0,0) to (0,7)
T1 loads (1,0) to (1,7)
...
T15 loads (15,0) to (15,7)
T16 loads (0,8) to (0,15)
T17 loads (1,8) to (1,15)
...
T31 loads (15,8) to (15,15)
Threads T0, T2, ... T14 accesses the same bank similarly threads T1, T3, ... T15 accesses the same bank thus a 8-way bank conflict happens during the load. The same is true for thread group T16, T18, ... T30 and thread group T17, T19, ..., T31.
Since each thread needs to access 8 consecutive values, thus during permutation we must take care that we permute using groups of 8 columns and since two consecutive rows do not cause bank conflicts we can take care that permutation does not happen between set of two consecutive rows. Thus, we are grouping the values in the 32x32 matrix by 2 rows and 8 columns or in other words we are doing swizzling of columns on 16x4 matrix where each element of the 16x4 matrix is a block of 2x8 FP16 elements. That is why in the XOR operation in the function get_swizzled_index we are dividing the row by 2 and column by 8. The exact formula is derived to take care of different dimensions of matrices.
We will deep dive into swizzling in the next post to understand the proofs behind why this works and how the exact formula is derived step by step.
Time taken to multiply two 4096x4096 matrices is around 13.3683 ms
Kernel 10 - cuBLAS
Lastly for the sake of completion, we are going to show a FP16 matrix multiplication using cuBLAS library in CUDA.
// Define some error checking macros.
#define cudaErrCheck(stat) { cudaErrCheck_((stat), __FILE__, __LINE__); }
#define cublasErrCheck(stat) { cublasErrCheck_((stat), __FILE__, __LINE__); }
#define curandErrCheck(stat) { curandErrCheck_((stat), __FILE__, __LINE__); }
void gemm_fp16_cublas(
const __half *a_fp16,
const __half *b_fp16,
float *c_fp32,
const float alpha,
const float beta,
const int m,
const int n,
const int k
) {
cublasHandle_t handle;
cublasErrCheck(cublasCreate(&handle));
// Use tensor cores
cublasErrCheck(cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH));
cublasErrCheck(
cublasGemmEx(
handle,
CUBLAS_OP_N, CUBLAS_OP_N,
m, n, k,
&alpha,
b_fp16, CUDA_R_16F, n,
a_fp16, CUDA_R_16F, k,
&beta,
c_fp32, CUDA_R_32F, n,
CUDA_R_32F, CUBLAS_GEMM_DEFAULT_TENSOR_OP
)
);
cublasDestroy(handle);
}
float *d_gpu_fp32;
cudaErrCheck(cudaMallocManaged(&d_gpu_fp32, m * n * sizeof(float)));
for (auto i = 0; i < m*n; i++) d_gpu_fp32[i] = 0.0f;
gemm_fp16_cublas(a_fp16, b_fp16, d_gpu_fp32, 1.0, 0.0, m, n, k);
cudaErrCheck(cudaFree(d_gpu_fp32));
Time taken to multiply two 4096x4096 matrices is around 47.3037 ms